🧠
2 mémoires pour des IAs
qui n'oublient plus
2 memories for AIs
that never forget
2 Speicher für KIs,
die nie vergessen
Live Memory + Graph Memory — Architecture mémoire pour agents IA
Live Memory + Graph Memory — Memory architecture for AI agents
Live Memory + Graph Memory — Speicherarchitektur für KI-Agenten
Christophe Lesur — Cloud Temple
Open Source
Apache 2.0
MCP Protocol
Un LLM, c'est quoi au fond ?
What exactly is an LLM?
Was genau ist ein LLM?
Pour ceux qui viennent du réseau, c'est simple
For networking folks, it's quite simple
Für Netzwerkexperten ist das ganz einfach
f(x) = y
prompt → modèle (200 milliards de paramètres) → réponse
prompt → model (200 billion parameters) → response
Prompt → Modell (200 Milliarden Parameter) → Antwort
C'est une fonction mathématique. Rien de plus.
It's a mathematical function. Nothing more.
Es ist eine mathematische Funktion. Nichts weiter.
- 📥 Une entrée — votre prompt + contexte
- ⚙️ Un calcul — multiplication de matrices
- 📤 Une sortie — la réponse générée
- 📥 An input — your prompt + context
- ⚙️ A calculation — matrix multiplication
- 📤 An output — the generated response
- 📥 Ein Eingang — Ihr Prompt + Kontext
- ⚙️ Eine Berechnung — Matrixmultiplikation
- 📤 Ein Ausgang — die generierte Antwort
Comme un serveur web qui traite une requête HTTP :
c'est 100% stateless.
Aucune mémoire entre deux appels.
Zéro. Nada.
💡 Un concept familier pour les gens du réseau !
Like a web server handling an HTTP request:
it's 100% stateless.
No memory between two calls.
Zero. Nada.
💡 A familiar concept for networking folks!
Wie ein Webserver, der eine HTTP-Anfrage verarbeitet:
es ist 100% zustandslos.
Kein Speicher zwischen zwei Aufrufen.
Null. Nada.
💡 Ein vertrautes Konzept für Netzwerkexperten!
L'amnésie en action
Amnesia in action
Amnesie in Aktion
Ce qui se passe à chaque nouvelle session
What happens in every new session
Was in jeder neuen Sitzung passiert
🟢 Session 1 — 14h00
🟢 Session 1 — 2:00 PM
🟢 Sitzung 1 — 14:00 Uhr
L'agent a analysé votre infrastructure, compris les dépendances réseau,
pris des décisions d'architecture, documenté les flux, écrit du code...
The agent analyzed your infrastructure, understood network dependencies,
made architectural decisions, documented flows, wrote code...
Der Agent hat Ihre Infrastruktur analysiert, Netzwerkabhängigkeiten verstanden,
Architekturentscheidungen getroffen, Datenflüsse dokumentiert, Code geschrieben...
→ Productif, contextualisé, pertinent
→ Productive, contextualized, relevant
→ Produktiv, kontextualisiert, relevant
🔴 Session 2 — Le lendemain
🔴 Session 2 — Next day
🔴 Sitzung 2 — Nächster Tag
"Bonjour ! Comment puis-je vous aider ?"
"Hello! How can I help you today?"
"Hallo! Wie kann ich Ihnen heute helfen?"
→ Tout est perdu. Il repart de zéro.
→ Everything is lost. Starting from scratch.
→ Alles ist verloren. Er fängt bei null an.
C'est comme si votre meilleur ingénieur réseau avait un reset total chaque matin.
Et si vous avez 3 agents IA sur le même projet ? Chacun dans sa bulle. Aucune coordination.
It's as if your best network engineer had a total reset every morning.
And what if you have 3 AI agents on the same project? Each in their own bubble. No coordination.
Es ist, als ob Ihr bester Netzwerkingenieur jeden Morgen einen kompletten Reset hätte.
Und wenn Sie 3 KI-Agenten im selben Projekt haben? Jeder in seiner eigenen Blase. Keine Koordination.
Comment fonctionne notre mémoire ?
How does our memory work?
Wie funktioniert unser Gedächtnis?
Le cerveau humain a résolu ce problème depuis des millions d'années
The human brain solved this problem millions of years ago
Das menschliche Gehirn hat dieses Problem vor Millionen Jahren gelöst
🔴 Mémoire de travail
🔴 Working Memory
🔴 Arbeitsgedächtnis
Hippocampe
Hippocampus
Hippocampus
- ⚡ Rapide, volatile
- 📝 Notes mentales en cours
- 🔄 Capacité limitée (~7 éléments)
- ⏱️ Durée : minutes à heures
- ⚡ Fast, volatile
- 📝 Ongoing mental notes
- 🔄 Limited capacity (~7 items)
- ⏱️ Duration: minutes to hours
- ⚡ Schnell, flüchtig
- 📝 Laufende mentale Notizen
- 🔄 Begrenzte Kapazität (~7 Elemente)
- ⏱️ Dauer: Minuten bis Stunden
🟢 Mémoire long terme
🟢 Long-term Memory
🟢 Langzeitgedächtnis
Néocortex
Neocortex
Neokortex
- 🏗️ Structurée, durable
- 🔗 Réseau de concepts reliés
- ♾️ Capacité quasi-illimitée
- ⏱️ Durée : jours à années
- 🏗️ Structured, durable
- 🔗 Network of linked concepts
- ♾️ Near-limitless capacity
- ⏱️ Duration: days to years
- 🏗️ Strukturiert, langlebig
- 🔗 Netzwerk verbundener Konzepte
- ♾️ Nahezu unbegrenzte Kapazität
- ⏱️ Dauer: Tage bis Jahre
Le sommeil consolide : il trie les souvenirs de la journée et les intègre dans la mémoire long terme.
C'est exactement ce que fait notre architecture.
Sleep consolidates: it sorts the day's memories and integrates them into long-term memory.
This is exactly what our architecture does.
Schlaf konsolidiert: Er sortiert die Erinnerungen des Tages und integriert sie ins Langzeitgedächtnis.
Genau das tut unsere Architektur.
Notre réponse : 2 mémoires
Our answer: 2 memories
Unsere Antwort: 2 Speicher
Inspirées directement de l'architecture cognitive humaine
Directly inspired by human cognitive architecture
Direkt von der menschlichen kognitiven Architektur inspiriert
🔴Live Memory
Mémoire de travail
Working memory
Arbeitsgedächtnis
→
🧠
Consolidation LLM
LLM Consolidation
LLM-Konsolidierung
"Trie et structure"
"Sorts and structures"
"Sortiert und strukturiert"
→
📘Memory Bank
Documentation structurée
Structured documentation
Strukturierte Dokumentation
→
🟢Graph Memory
Mémoire long terme
Long-term memory
Langzeitgedächtnis
| 🔴 Live Memory | 🟢 Graph Memory |
|---|
| Rôle | Mémoire de travail partagée | Base de connaissances permanente |
| Durée | Session / projet | Permanent |
| Contenu | Notes live + Bank Markdown | Entités + Relations + Embeddings |
| Stack | S3 seul (pas de BDD !) | Neo4j + Qdrant + S3 |
| Analogie | Tableau blanc + cahier de projet | Bibliothèque avec index |
| 🔴 Live Memory | 🟢 Graph Memory |
|---|
| Role | Shared working memory | Permanent knowledge base |
| Duration | Session / project | Permanent |
| Content | Live notes + Markdown Bank | Entities + Relations + Embeddings |
| Stack | S3 only (no DB!) | Neo4j + Qdrant + S3 |
| Analogy | Whiteboard + project notebook | Library with index |
| 🔴 Live Memory | 🟢 Graph Memory |
|---|
| Rolle | Gemeinsames Arbeitsgedächtnis | Permanente Wissensdatenbank |
| Dauer | Sitzung / Projekt | Permanent |
| Inhalt | Live-Notizen + Markdown-Bank | Entitäten + Relationen + Embeddings |
| Stack | Nur S3 (keine DB!) | Neo4j + Qdrant + S3 |
| Analogie | Whiteboard + Projektnotizbuch | Bibliothek mit Index |
📖 Réf : Tran et al., 2025 — "Multi-Agent Collaboration Mechanisms: A Survey of LLMs" (arXiv:2501.06322)
📖 Ref: Tran et al., 2025 — "Multi-Agent Collaboration Mechanisms: A Survey of LLMs" (arXiv:2501.06322)
📖 Ref: Tran et al., 2025 — "Multi-Agent Collaboration Mechanisms: A Survey of LLMs" (arXiv:2501.06322)
🔴 Live Memory
🔴 Live Memory
🔴 Live Memory
Le tableau blanc partagé — chaque agent écrit des notes atomiques en temps réel
The shared whiteboard — each agent writes atomic notes in real-time
Das gemeinsame Whiteboard — jeder Agent schreibt atomare Notizen in Echtzeit
🤖 Agent Cline
observation Build OK, 0 erreursdecision REST plutôt que gRPCtodo Tester l'auth OAuth2
🤖 Agent Claude
observation Latence API > 200msquestion Redis ou Memcached ?progress Module auth terminé
🤖 Agent QA
issue Fuite mémoire en chargeinsight Pattern retry efficaceobservation 95% couverture tests
🤖 Agent Cline
observation Build OK, 0 errorsdecision REST over gRPCtodo Test OAuth2 auth
🤖 Agent Claude
observation API Latency > 200msquestion Redis or Memcached?progress Auth module finished
🤖 Agent QA
issue Memory leak under loadinsight Retry pattern effectiveobservation 95% test coverage
🤖 Agent Cline
observation Build OK, 0 Fehlerdecision REST statt gRPCtodo OAuth2-Auth testen
🤖 Agent Claude
observation API-Latenz > 200msquestion Redis oder Memcached?progress Auth-Modul fertiggestellt
🤖 Agent QA
issue Speicherleck unter Lastinsight Retry-Pattern effektivobservation 95% Testabdeckung
Architecture : Append-Only sur S3
Architecture: Append-Only on S3
Architektur: Append-Only auf S3
- 📦 Pas de base de données — juste du S3
- 🔒 Pas de conflit — 1 note = 1 fichier unique horodaté
- 🐜 Stigmergie — communication indirecte via l'environnement
- 📦 No database — just S3
- 🔒 No conflicts — 1 note = 1 unique timestamped file
- 🐜 Stigmergy — indirect communication via environment
- 📦 Keine Datenbank — nur S3
- 🔒 Keine Konflikte — 1 Notiz = 1 eindeutige Datei mit Zeitstempel
- 🐜 Stigmergie — indirekte Kommunikation über die Umgebung
Comme les fourmis qui communiquent par les phéromones, pas par la parole. Chaque agent laisse des traces que les autres lisent.
Like ants communicating via pheromones, not speech. Each agent leaves traces for others to read.
Wie Ameisen, die über Pheromone kommunizieren, nicht durch Sprache. Jeder Agent hinterlässt Spuren, die andere lesen.
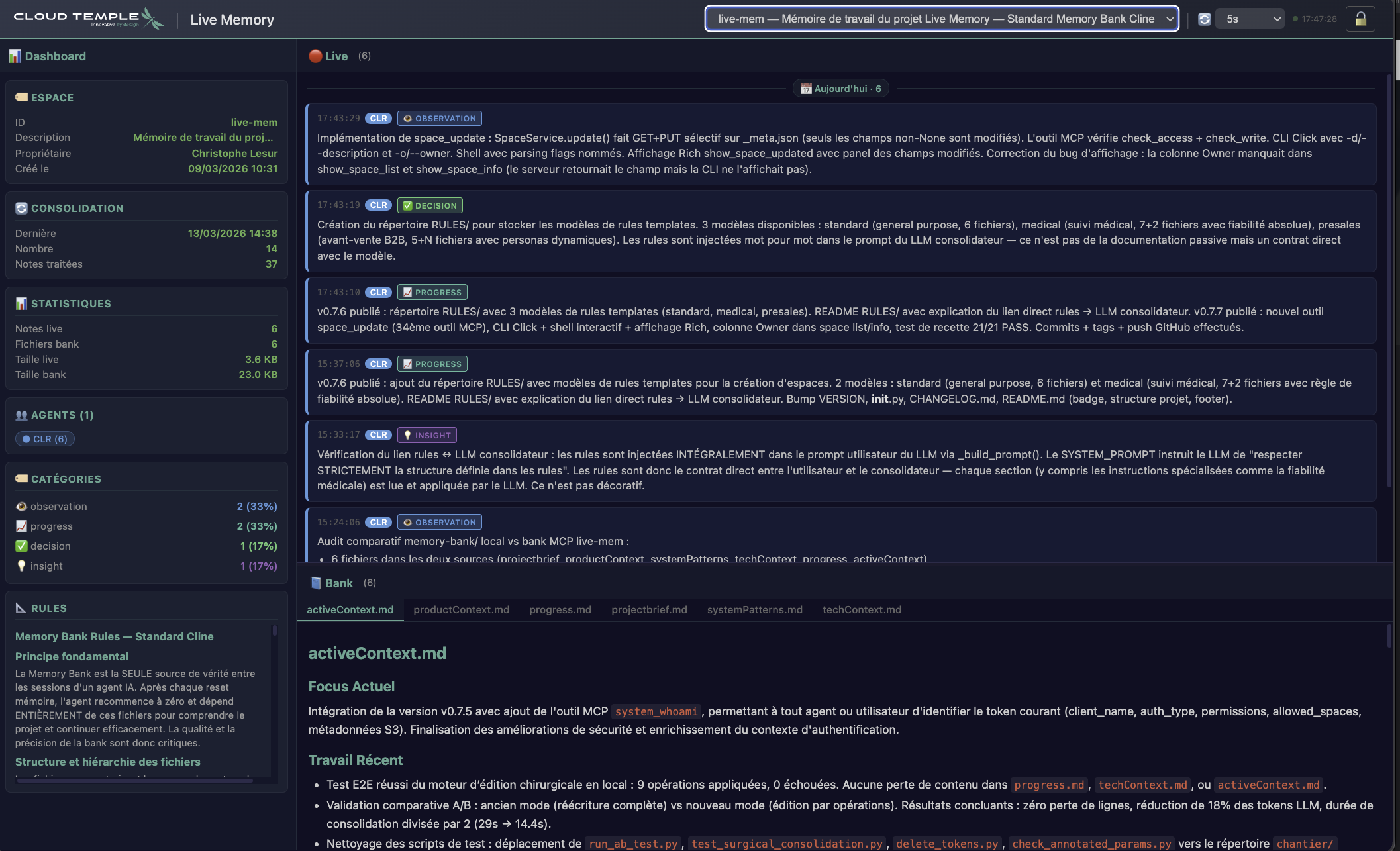
🖥️ L'interface Live Memory en action
🖥️ Live Memory interface in action
🖥️ Live-Memory-Benutzeroberfläche in Aktion
Dashboard + Timeline live + Memory Bank — tout le contexte d'un projet en un coup d'œil
Dashboard + Live Timeline + Memory Bank — full project context at a glance
Dashboard + Live-Timeline + Memory Bank — der gesamte Projektkontext auf einen Blick
📊 Dashboard (agents, stats, rules)
🔴 Timeline live (notes groupées par date)
📘 Bank Viewer (Markdown consolidé)
🔄 Auto-refresh intelligent
📊 Dashboard (agents, stats, rules)
🔴 Live Timeline (notes grouped by date)
📘 Bank Viewer (consolidated Markdown)
🔄 Smart auto-refresh
📊 Dashboard (Agenten, Statistiken, Regeln)
🔴 Live-Timeline (Notizen nach Datum gruppiert)
📘 Bank Viewer (konsolidiertes Markdown)
🔄 Intelligente automatische Aktualisierung
🧠 La consolidation LLM
🧠 LLM Consolidation
🧠 LLM-Konsolidierung
Du chaos à la structure — le "sommeil" de notre architecture
From chaos to structure — the "sleep" of our architecture
Vom Chaos zur Struktur — der "Schlaf" unserer Architektur
📝Notes brutes47 notes · 3 agents
→
🧠LLMRules + Notes + Bank
→
📘Bank mise à jourÉdition chirurgicale
→
🗑️Notes purgéesIntégrées → supprimées
📝Raw Notes47 notes · 3 agents
→
🧠LLMRules + Notes + Bank
→
📘Updated BankSurgical editing
→
🗑️Purged NotesIntegrated → deleted
📝Rohe Notizen47 Notizen · 3 Agenten
→
🧠LLMRegeln + Notizen + Bank
→
📘Bank-UpdateChirurgische Bearbeitung
→
🗑️Gelöschte NotizenIntegriert → gelöscht
❌ Approche naïve
Le LLM réécrit tout le fichier à chaque consolidation.
Syndrome "photocopie de photocopie" :
Dégradation progressive de l'information à chaque passe.
✅ Notre approche : édition chirurgicale
Le LLM produit des opérations d'édition par section Markdown.
Ce qui n'est pas touché reste identique bit-à-bit.
Zéro perte d'information. ~50% tokens en moins.
❌ Naive approach
The LLM rewrites the entire file on each consolidation.
"Photocopy of a photocopy" syndrome:
Progressive degradation of information with each pass.
✅ Our approach: surgical editing
The LLM produces Markdown section editing operations.
What isn't touched remains bit-for-bit identical.
Zero information loss. ~50% fewer tokens.
❌ Naiver Ansatz
Das LLM schreibt die gesamte Datei bei jeder Konsolidierung neu.
"Fotokopie einer Fotokopie"-Syndrom:
Schleichende Verschlechterung der Informationen bei jedem Durchgang.
✅ Unser Ansatz: chirurgische Bearbeitung
Das LLM erstellt Markdown-Abschnittsbearbeitungsvorgänge.
Was nicht berührt wird, bleibt bitgenau identisch.
Null Informationsverlust. ~50% weniger Token.
Les Rules sont le contrat immuable : elles définissent la structure de la bank. Le LLM s'y conforme systématiquement.
The Rules are the immutable contract: they define the bank's structure. The LLM systematically complies with them.
Die Regeln (Rules) sind der unveränderliche Vertrag: Sie definieren die Struktur der Bank. Das LLM hält sich systematisch daran.
📐 Les Rules en action
📐 Rules in action
📐 Regeln (Rules) in Aktion
Le contrat immuable qui structure la mémoire — défini une fois, respecté toujours
The immutable contract structuring the memory — defined once, respected always
Der unveränderliche Vertrag, der den Speicher strukturiert — einmal definiert, immer respektiert
Exemple : Rules "Standard Dev"
Example: "Standard Dev" Rules
Beispiel: "Standard Dev" Regeln
## Structure de la Memory Bank
projectbrief.md (fondation)
├── productContext.md pourquoi le projet existe
├── systemPatterns.md architecture & patterns
└── techContext.md stack technique & setup
└── activeContext.md focus actuel
└── progress.md journal d'avancement
## Mapping notes → fichiers
observation → activeContext.md
decision → systemPatterns.md
progress → progress.md
issue → progress.md (problèmes connus)
insight → systemPatterns.md
## Memory Bank Structure
projectbrief.md (foundation)
├── productContext.md why the project exists
├── systemPatterns.md architecture & patterns
└── techContext.md tech stack & setup
└── activeContext.md current focus
└── progress.md progress journal
## Note → file mapping
observation → activeContext.md
decision → systemPatterns.md
progress → progress.md
issue → progress.md (known issues)
insight → systemPatterns.md
## Memory Bank Struktur
projectbrief.md (Fundament)
├── productContext.md Warum das Projekt existiert
├── systemPatterns.md Architektur & Muster
└── techContext.md Tech-Stack & Setup
└── activeContext.md aktueller Fokus
└── progress.md Fortschrittsjournal
## Notiz → Datei-Mapping
observation → activeContext.md
decision → systemPatterns.md
progress → progress.md
issue → progress.md (bekannte Probleme)
insight → systemPatterns.md
4 templates fournis
4 templates provided
4 Vorlagen enthalten
🖥️ Standard Dev
6 fichiers — projets logiciels, architecture, code
🖥️ Standard Dev
6 files — software projects, architecture, code
🖥️ Standard Dev
6 Dateien — Softwareprojekte, Architektur, Code
📚 Écriture de livre
6 fichiers — narratif, chapitres, style, compteur de mots
📚 Book Writing
6 files — narrative, chapters, style, word count
📚 Buch schreiben
6 Dateien — Erzählung, Kapitel, Stil, Wortzahl
🏥 Suivi médical
7+2 fichiers — patients, traitements, fiabilité absolue
🏥 Medical Follow-up
7+2 files — patients, treatments, absolute reliability
🏥 Medizinische Betreuung
7+2 Dateien — Patienten, Behandlungen, absolute Zuverlässigkeit
💼 Avant-vente B2B
5+N fichiers — personas dynamiques, qualification, offre
💼 B2B Presales
5+N files — dynamic personas, qualification, proposal
💼 B2B Pre-Sales
5+N Dateien — dynamische Personas, Qualifizierung, Angebot
Les rules sont immuables après création. Elles garantissent que la mémoire garde toujours la même structure, quel que soit le nombre de consolidations.
Rules are immutable after creation. They ensure the memory always keeps the same structure, regardless of the number of consolidations.
Regeln sind nach Erstellung unveränderlich. Sie stellen sicher, dass der Speicher immer dieselbe Struktur behält, unabhängig von der Anzahl der Konsolidierungen.
🟢 Graph Memory
🟢 Graph Memory
🟢 Graph Memory
La bibliothèque intelligente — un graphe de connaissances, pas une boîte de chunks
The smart library — a knowledge graph, not a box of chunks
Die smarte Bibliothek — ein Wissensgraph, keine Kiste voller Chunks
📄DocumentPDF, DOCX, MD, HTML, CSV
→
🧠LLM + OntologieExtraction guidée
→
🔗Graphe Neo4jEntités + Relations typées
+
📐QdrantChunks vectoriels
📄DocumentPDF, DOCX, MD, HTML, CSV
→
🧠LLM + OntologyGuided extraction
→
🔗Neo4j GraphEntities + Typed relations
+
📐QdrantVector chunks
📄DokumentPDF, DOCX, MD, HTML, CSV
→
🧠LLM + OntologieGeführte Extraktion
→
🔗Neo4j-GraphEntitäten + Typisierte Relationen
+
📐QdrantVektor-Chunks
Les ontologies : le vocabulaire métier qui guide l'extraction
⚖️ Legal
22 entités · 22 relations
☁️ Cloud
27 entités · 19 relations
🔧 Managed Svc
20 entités · 16 relations
💼 Presales
28 entités · 30 relations
📋 General
24 entités · 22 relations
Ontologies: the business vocabulary that guides extraction
⚖️ Legal
22 entities · 22 relations
☁️ Cloud
27 entities · 19 relations
🔧 Managed Svc
20 entities · 16 relations
💼 Presales
28 entities · 30 relations
📋 General
24 entities · 22 relations
Ontologien: das Geschäftsvokabular, das die Extraktion steuert
⚖️ Legal
22 Entitäten · 22 Relationen
☁️ Cloud
27 Entitäten · 19 Relationen
🔧 Managed Svc
20 Entitäten · 16 Relationen
💼 Presales
28 Entitäten · 30 Relationen
📋 General
24 Entitäten · 22 Relationen
L'ontologie dit au LLM quoi chercher dans les documents. Pas de relations génériques RELATED_TO : des types explicites comme DEFINES, APPLIES_TO, REFERENCES.
The ontology tells the LLM what to look for in documents. No generic RELATED_TO relations: explicit types like DEFINES, APPLIES_TO, REFERENCES.
Die Ontologie sagt dem LLM, wonach es in Dokumenten suchen soll. Keine generischen RELATED_TO-Beziehungen: explizite Typen wie DEFINES, APPLIES_TO, REFERENCES.
⚖️ L'ontologie en action
⚖️ Ontology in action
⚖️ Ontologie in Aktion
Exemple : ontologie "Legal" pour l'analyse de contrats
Example: "Legal" ontology for contract analysis
Beispiel: "Legal"-Ontologie für Vertragsanalysen
entity_types:
- Party # "Cloud Temple SAS", "TechCorp"
- Clause # "Article 12 - Réversibilité"
- Amount # "8 500 EUR HT/mois"
- Duration # "36 mois (durée initiale)"
- SLA # "99.95% disponibilité"
- Certification # "SecNumCloud", "HDS"
- Obligation # "Garantie de disponibilité"
... (22 types au total)
relation_types:
- PARTY_TO # Client → Contrat
- HAS_AMOUNT # Prestation → 50 000 EUR
- HAS_SLA # Service → 99.95%
- GUARANTEES # Cloud Temple → SecNumCloud
- OBLIGATES # Clause → Client
- GOVERNED_BY # Traitement → RGPD
... (22 types au total)
entity_types:
- Party # "Cloud Temple SAS", "TechCorp"
- Clause # "Article 12 - Reversibility"
- Amount # "8,500 EUR excl. tax/month"
- Duration # "36 months (initial term)"
- SLA # "99.95% availability"
- Certification # "SecNumCloud", "HDS"
- Obligation # "Availability guarantee"
... (22 types in total)
relation_types:
- PARTY_TO # Client → Contract
- HAS_AMOUNT # Service → 50,000 EUR
- HAS_SLA # Service → 99.95%
- GUARANTEES # Cloud Temple → SecNumCloud
- OBLIGATES # Clause → Client
- GOVERNED_BY # Processing → GDPR
... (22 types in total)
entity_types:
- Party # "Cloud Temple SAS", "TechCorp"
- Clause # "Artikel 12 - Reversibilität"
- Amount # "8.500 EUR netto/Monat"
- Duration # "36 Monate (Anfangslaufzeit)"
- SLA # "99.95% Verfügbarkeit"
- Certification # "SecNumCloud", "HDS"
- Obligation # "Verfügbarkeitsgarantie"
... (22 Typen insgesamt)
relation_types:
- PARTY_TO # Kunde → Vertrag
- HAS_AMOUNT # Leistung → 50.000 EUR
- HAS_SLA # Service → 99.95%
- GUARANTEES # Cloud Temple → SecNumCloud
- OBLIGATES # Klausel → Kunde
- GOVERNED_BY # Verarbeitung → DSGVO
... (22 Typen insgesamt)
Le LLM reçoit l'ontologie + le document → extrait exactement les entités et relations définies. Pas de bruit, pas d'hallucination structurelle.
The LLM receives the ontology + the document → extracts exactly the defined entities and relations. No noise, no structural hallucination.
Das LLM erhält die Ontologie + das Dokument → extrahiert exakt die definierten Entitäten und Beziehungen. Kein Rauschen, keine strukturelle Halluzination.
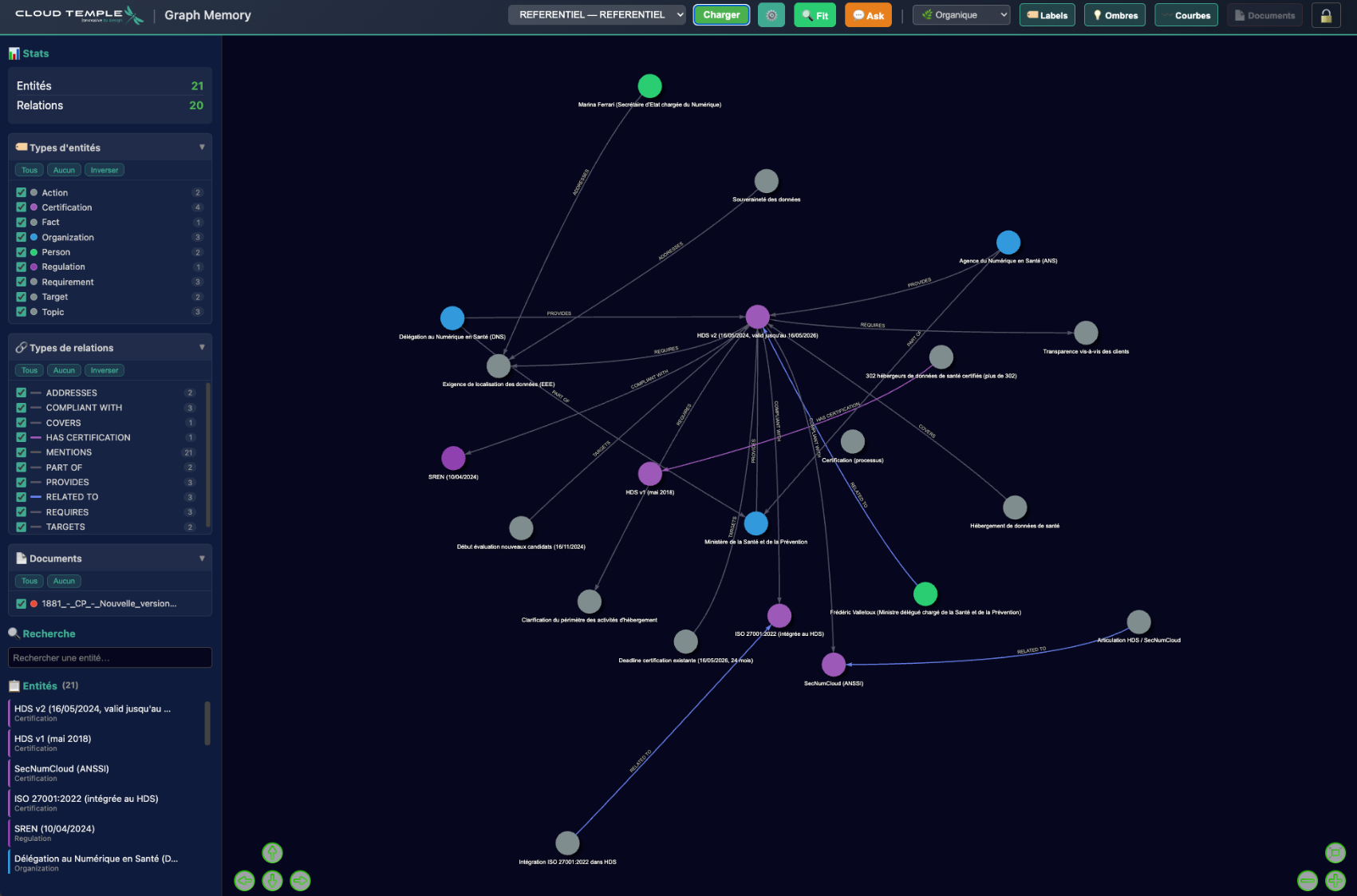
Résultat : le graphe de connaissances
Result: the knowledge graph
Ergebnis: der Wissensgraph
Interface Graph Memory — Graphe interactif avec filtrage par types d'entités et de relations
Graph Memory Interface — Interactive graph with filtering by entity and relation types
Graph Memory Interface — Interaktiver Graph mit Filterung nach Entitäts- und Beziehungstypen
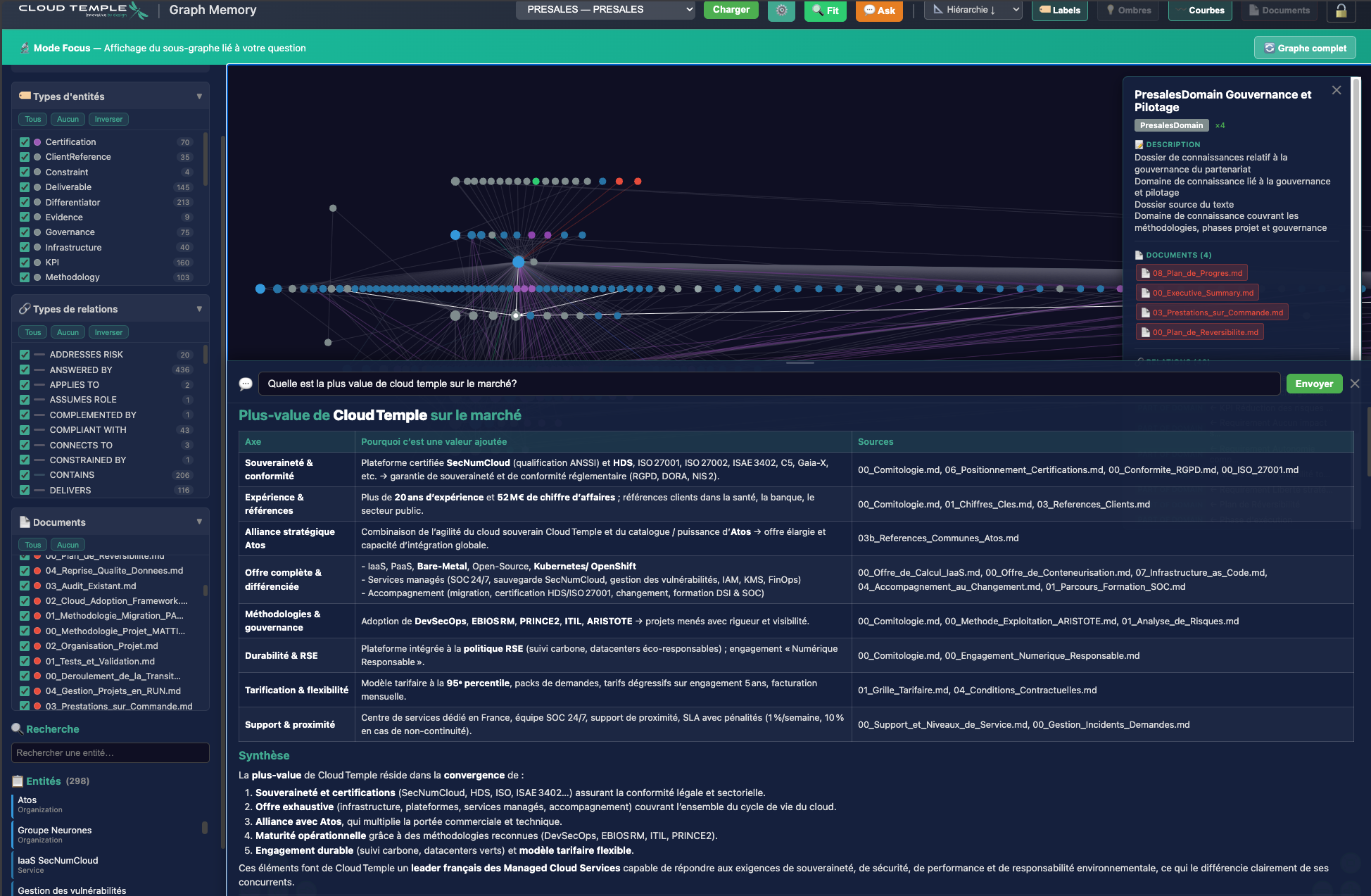
💬 Interroger le graphe en langage naturel
💬 Querying the graph in natural language
💬 Den Graphen in natürlicher Sprache abfragen
Le panneau ASK — question → réponse LLM avec citations des documents sources
The ASK panel — question → LLM answer with citations to source documents
Das ASK-Panel — Frage → LLM-Antwort mit Zitaten aus Quelldokumenten
🗣️ Question en langage naturel
📊 Réponse Markdown (tableaux, listes, code)
📄 Citations des documents sources
🔬 Mode Focus : sous-graphe pertinent
🗣️ Natural language question
📊 Markdown answer (tables, lists, code)
📄 Source document citations
🔬 Focus Mode: relevant sub-graph
🗣️ Frage in natürlicher Sprache
📊 Markdown-Antwort (Tabellen, Listen, Code)
📄 Zitate aus Quelldokumenten
🔬 Fokus-Modus: relevanter Teil-Graph
Pourquoi un graphe ?
Why a graph?
Warum ein Graph?
Graph-First vs RAG vectoriel classique
Graph-First vs Classic Vector RAG
Graph-First vs Klassisches Vektor-RAG
RAG vectoriel classique
- 📦 Document → chunks → embeddings
- 🔍 Recherche par similitude cosinus
- ❓ Chunks anonymes
- 🎯 Approximatif (voisinage sémantique)
- ↔️ Recherche unidirectionnelle
Comme chercher dans Google
avec juste des mots-clés
Classic Vector RAG
- 📦 Document → chunks → embeddings
- 🔍 Cosine similarity search
- ❓ Anonymous chunks
- 🎯 Approximate (semantic neighborhood)
- ↔️ Unidirectional search
Like searching on Google
with just keywords
Klassisches Vektor-RAG
- 📦 Dokument → Chunks → Embeddings
- 🔍 Kosinus-Ähnlichkeitssuche
- ❓ Anonyme Chunks
- 🎯 Ungefähr (semantische Nachbarschaft)
- ↔️ Unidirektionale Suche
Wie die Suche auf Google
nur mit Stichwörtern
VS
Graph-First (notre approche)
- 🔗 Document → entités + relations
- 🗺️ Navigation dans un graphe structuré
- 📄 Chaque entité liée à son document source
- 🎯 Précis (relations explicites, typées)
- 🔀 Navigation multi-hop
Comme naviguer Wikipedia :
de lien en lien, avec contexte
Graph-First (our approach)
- 🔗 Document → entities + relations
- 🗺️ Navigation in a structured graph
- 📄 Each entity linked to its source document
- 🎯 Precise (explicit, typed relations)
- 🔀 Multi-hop navigation
Like browsing Wikipedia:
from link to link, with context
Graph-First (unser Ansatz)
- 🔗 Dokument → Entitäten + Relationen
- 🗺️ Navigation in einem strukturierten Graphen
- 📄 Jede Entität mit ihrem Quelldokument verknüpft
- 🎯 Präzise (explizite, typisierte Relationen)
- 🔀 Multi-Hop-Navigation
Wie beim Durchsuchen von Wikipedia:
von Link zu Link, mit Kontext
Graph-Guided RAG : le meilleur des deux mondes
❶GrapheIdentifie entités + documents
→
❷QdrantChunks DANS ces documents
→
❸LLMRéponse avec citations
Le graphe cible, le vectoriel précise. Pas de bruit.
Graph-Guided RAG: the best of both worlds
❶GraphIdentifies entities + documents
→
❷QdrantChunks WITHIN those documents
→
❸LLMAnswer with citations
The graph targets, the vector refines. No noise.
Graph-Guided RAG: das Beste aus beiden Welten
❶GraphIdentifiziert Entitäten + Dokumente
→
❷QdrantChunks IN diesen Dokumenten
→
❸LLMAntwort mit Zitaten
Der Graph zielt, der Vektor präzisiert. Kein Rauschen.
🌉 Le pont entre les deux
🌉 The bridge between the two
🌉 Die Brücke zwischen beiden
De la mémoire de travail à la mémoire permanente
From working memory to permanent memory
Vom Arbeitsgedächtnis zum permanenten Speicher
Agents IA (Cline, Claude, ...)
▼ live_note() — ~50ms
🔴 LIVE MEMORY
append-only sur S3
Notes temps réel
7 catégories · multi-agents
▼ bank_consolidate() — ~15s
📘 MEMORY BANK
Édition chirurgicale
Markdown structuré
conforme aux Rules
▼ graph_push() — ~30s/fichier via MCP
🟢 GRAPH MEMORY
Neo4j + Qdrant + S3
Entités + Relations
Interrogeable en langage naturel
AI Agents (Cline, Claude, ...)
▼ live_note() — ~50ms
🔴 LIVE MEMORY
append-only on S3
Real-time notes
7 categories · multi-agent
▼ bank_consolidate() — ~15s
📘 MEMORY BANK
Surgical editing
Structured Markdown
compliant with Rules
▼ graph_push() — ~30s/file via MCP
🟢 GRAPH MEMORY
Neo4j + Qdrant + S3
Entities + Relations
Queryable in natural language
KI-Agenten (Cline, Claude, ...)
▼ live_note() — ~50ms
🔴 LIVE MEMORY
append-only auf S3
Echtzeit-Notizen
7 Kategorien · Multi-Agent
▼ bank_consolidate() — ~15s
📘 MEMORY BANK
Chirurgische Bearbeitung
Strukturiertes Markdown
gemäß den Regeln (Rules)
▼ graph_push() — ~30s/Datei via MCP
🟢 GRAPH MEMORY
Neo4j + Qdrant + S3
Entitäten + Relationen
Abfragbar in natürlicher Sprache
⚡ Écrire vite
- Notes live : ~50ms
- Consolidation : ~15 secondes
- → Zéro friction pour les agents
🏛️ Capitaliser durablement
- Graph push : ~30s/fichier
- Interrogation en langage naturel
- → Les connaissances survivent aux projets
⚡ Write fast
- Live notes: ~50ms
- Consolidation: ~15 seconds
- → Zero friction for agents
🏛️ Capitalize lastingly
- Graph push: ~30s/file
- Natural language querying
- → Knowledge survives projects
⚡ Schnell schreiben
- Live-Notizen: ~50ms
- Konsolidierung: ~15 Sekunden
- → Keine Reibung für Agenten
🏛️ Dauerhaft kapitalisieren
- Graph push: ~30s/Datei
- Abfrage in natürlicher Sprache
- → Wissen überlebt Projekte
🏗️ Architecture technique
🏗️ Technical Architecture
🏗️ Technische Architektur
Vue réseau — ce que vous aimez voir
Network view — what you like to see
Netzwerkansicht — was Sie gerne sehen
Agent ClineCline AgentCline-Agent
Agent ClaudeClaude AgentClaude-Agent
Agent X
▼ Streamable HTTP + Bearer Token
🔒 Caddy WAF (Coraza OWASP CRS)
Rate Limiting · TLS Let's Encrypt
← seul port :8080← only port :8080← nur Port :8080
Docker network interneInternal Docker networkInternes Docker-Netzwerk
🔴 Live Memory MCP (:8002)
35 outils35 tools35 Tools · Auth Bearer
→ S3 (Dell ECS / AWS)
→ LLMaaS (OpenAI API)
▼ MCP Streamable HTTP
🟢 Graph Memory MCP (:8002)
30 outils30 tools30 Tools · Auth Bearer
→ S3 + LLMaaS
→ Qdrant (embeddingsembeddingsEmbeddings)
→ Neo4j 5 (graphegraphGraph)
🔒 WAF OWASP CRS
🔑 Auth Bearer Token
📡 MCP Streamable HTTP
🐳 Docker non-root
📦 S3 source of truth
🔒 WAF OWASP CRS
🔑 Auth Bearer Token
📡 MCP Streamable HTTP
🐳 Docker non-root
📦 S3 source of truth
🔒 WAF OWASP CRS
🔑 Auth Bearer Token
📡 MCP Streamable HTTP
🐳 Docker non-root
📦 S3 Source of Truth
MCP (Model Context Protocol) = la norme émergente pour les outils d'IA (Anthropic, 2024).
Comme REST pour les humains, MCP pour les agents.
MCP (Model Context Protocol) = the emerging standard for AI tools (Anthropic, 2024).
Like REST for humans, MCP is for agents.
MCP (Model Context Protocol) = der aufkommende Standard für KI-Tools (Anthropic, 2024).
Wie REST für Menschen ist MCP für Agenten.
Des IAs qui capitalisent
AIs that capitalize
KIs, die kapitalisieren
❌ Avant
- Amnésie totale entre sessions
- Agents isolés, sans coordination
- Connaissances perdues
- RAG approximatif
✅ Après
- Mémoire de travail partagée
- Collaboration multi-agents
- Graphe de connaissances permanent
- Q&A précis avec sources
❌ Before
- Total amnesia between sessions
- Isolated agents, no coordination
- Lost knowledge
- Approximate RAG
✅ After
- Shared working memory
- Multi-agent collaboration
- Permanent knowledge graph
- Precise Q&A with sources
❌ Vorher
- Totale Amnesie zwischen Sitzungen
- Isolierte Agenten, keine Koordination
- Verlorenes Wissen
- Ungefähres RAG
✅ Nachher
- Gemeinsames Arbeitsgedächtnis
- Multi-Agenten-Kollaboration
- Permanenter Wissensgraph
- Präzises Q&A mit Quellen
Open Source · Apache 2.0 · Prêt pour la production
Christophe Lesur — Cloud Temple
Open Source · Apache 2.0 · Production Ready
Christophe Lesur — Cloud Temple
Open Source · Apache 2.0 · Produktionsbereit
Christophe Lesur — Cloud Temple